

Oracle Acceleron AI Networking on OCI — Explained
**The Shift from Ports to Planes
In traditional enterprise networking, I would normally consider factors involving port density, oversubscription, and leaf-spine hierarchies. However at hyperscale deminsions, those abstractions don’t hold. The network needs to become a computational system; a high-performance fabric with properties that determine how fast AI models can train or infer.
Oracle’s Acceleron architecture approaches solving this from first principles. Instead of designing a network around compute, it co-designs network, compute, and storage as a unified system.
Inside the Fabric: Radix, Breakouts, and Shuffle Cables
At the heart of Acceleron are high-radix switches. Network devices capable of connecting many endpoints directly. But Oracle pushes this further with port breakouts, turning each port (i.e. a 800 Gbps port on a 64-port switch) into multiple smaller connections (4 × 200 Gbps or 8 × 100 Gbps). This multiplies the effective radix of the switch, enabling fabrics with thousands of deterministic paths and minimal hops.
Shuffle cables distribute these connections across multiple planes, balancing load and isolating failures.
Individual fabric planes are fully independent spine-and-leaf CLOS networks, with their own control plane and data plane without sharing fate with their peers. In practice, this means a network fault in one plane (whether a failed link, a congested spine, or a misbehaving route) can’t impact traffic on any other plane. The result is a dramatically reduced blast radius for network faults and a fabric capable of maintaining deterministic performance, even during partial failures or maintenance events.
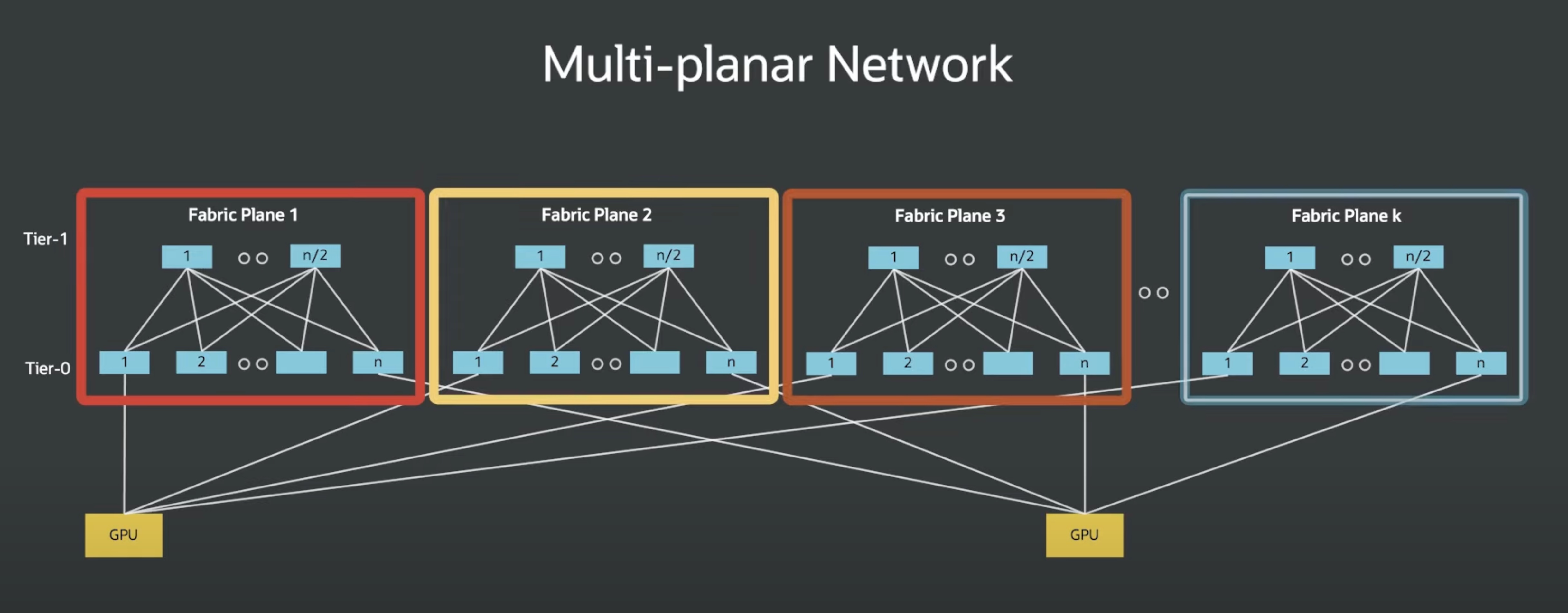
Combined, Acceleron creates a topology more akin to a supercomputer interconnect than a traditional cloud network.
Deterministic Performance for AI and HPC
Why does this matter? AI workloads are fundamentally communication-bound. When training a large model across hundres of thousands of GPUs, synchronization barriers depend on latency predictability, not just bandwidth.
Acceleron’s multiplanar design ensures that:
-
Each GPU or CPU node maintains a consistent latency profile, even under load.
-
Failure in one plane doesn’t affect others.
-
Traffic flows can be engineered deterministically for congestion-free operation.
It’s not just “bigger pipes.” It’s network architecture as a performance multiplier.
From Cisco to Oracle: A Personal Lens
During my time at Cisco, I saw firsthand how the evolution from Catalyst to Nexus and ACI redefined enterprise connectivity. We optimized for modularity, flexibility, and backward compatibility; all critical for diverse enterprise environments.
At Oracle, the design thinking shifts. OCI doesn’t need to optimize for legacy interoperability; it optimizes for AI-native performance. Acceleron represents that leap where the network fabric itself becomes an accelerator, orchestrating traffic as precisely as compute schedules instructions.
For someone who’s spent a career obsessed with how bits traverse a switch, it’s remarkable to see a cloud architecture that treats the network not as plumbing, but as core IP.
Closing Thought
AI has moved the bottleneck from compute to communication. Every microsecond counts when coordinating thousands of GPUs across a global fabric.
With Acceleron, Oracle is demonstrating that innovation in networking is just as critical as innovation in silicon — and that rethinking the data center fabric from first principles is how you unlock the next frontier of performance.
It’s the kind of system-level engineering that reminds me why I fell in love with networking in the first place.
If you’re curious about the details, Oracle’s official post is a great read (with an even better First Principles video hosted by: Pradeep Vincent, Jag Brar and David Becker):
Oracle Blog – First Principles: Oracle Acceleron and the Multiplanar Network Fabric