

Building a Personal AI Agent: From Packets to Prompts (Step-by-Step)
When I started my career at Cisco back in 2001, debugging meant tracing the path of a packet. Layer by layer, hop by hop, from source to destination. Twenty years later, working on cloud-native products and now at Oracle focusing on GPU infrastructure and AI, I’ve realized something: the same mental model applies to AI systems. There’s a request (the prompt), processing at multiple layers (embedding, retrieval, generation), and a response that travels back to the user.
This post walks through how I built CareerStack Agent—a personal knowledge AI agent that answers questions about my professional career. Along the way, I’ll trace the “path of a prompt” through Cloudflare’s developer platform, share the code that makes it work, and explain why I think Cloudflare is building something special for developers.
Try it yourself: mattv2.careerstack.app
View the code: github.com/mattkferguson/careerstack-agent
Why Build a Personal Knowledge Agent?
I wanted to apply what I’ve been learning. At Oracle, I’m working with customers on GPU-as-a-Service, AI/ML workloads, and cloud-native architectures. Before that, at Cisco, I led product launches for Kubernetes-as-a-Service, Infrastructure as Code with HashiCorp Terraform, and Zero Trust security solutions. I’ve spent years helping others build modern infrastructure—now I wanted to build something myself that tied together AI, cloud-native patterns, and the kind of observability and security thinking I’ve developed over two decades.
I wanted a grounded AI that only knows what I tell it. Large language models are impressive, but they hallucinate. They’ll confidently make up facts about your career if you let them. I wanted an agent that could answer questions about my experience—sourced exclusively from my resume, certifications, and blog—without inventing things. Could a recruiter or hiring manager use it? Maybe. Is it mostly a technical showcase? Absolutely.
Cloudflare is building something exciting. I’ve been using Cloudflare for years to host cloudnativenotes.com and other projects. What started as DNS and CDN has evolved into a complete developer platform: Workers, R2, AI Gateway, AI Search (AutoRAG), Vectorize, and more. The pricing is incredibly compelling—most of what I’m using here is free or nearly free. For someone who’s spent their career helping enterprises deploy million-dollar infrastructure, it’s remarkable what you can build today for almost nothing.
The Architecture
If you’ve worked with Kubernetes, this architecture will feel familiar. There’s an ingress layer (the Worker), a service layer (AI Search), a data layer (R2 + Vectorize), and observability/security (AI Gateway with Guardrails). Each component has a specific job.
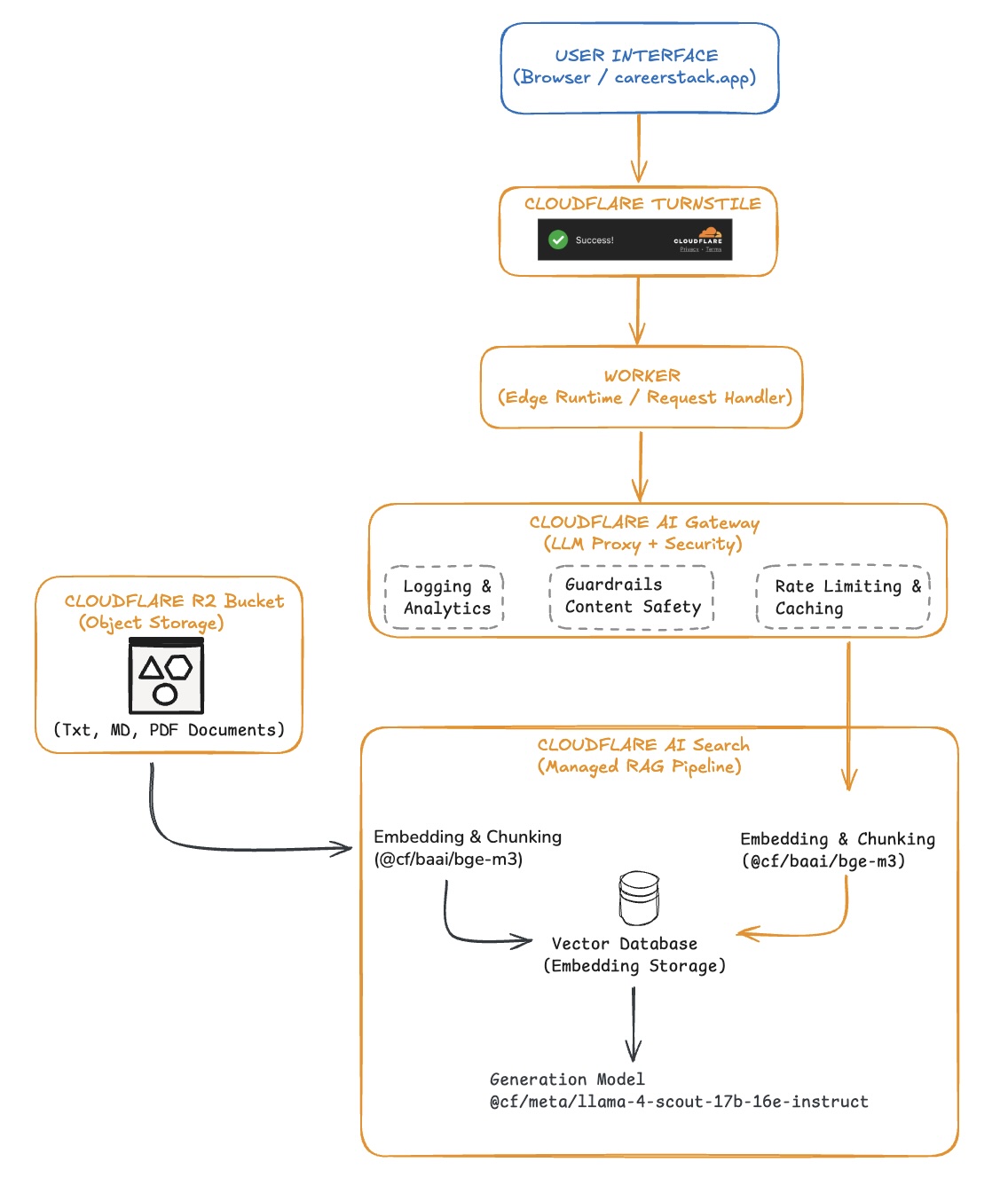
Cloudflare’s AI Search handles the entire RAG pipeline. It ingests my documents, chunks them, creates embeddings, stores them in a Vectorize database, and generates responses using a cloud managed GenAI model. I don’t need to wire up separate services for each step—it’s all managed.
Tracing the Path of a Prompt
Let’s follow a question through the system. I’ll show you the code at each hop so you can build something similar.
Hop 1: Bot Protection with Turnstile
Any public-facing endpoint needs protection. In my Cisco days working on security solutions, I learned that you always assume bad actors will find your APIs. Cloudflare Turnstile is their smart CAPTCHA alternative that runs invisible challenges to verify humans without those annoying “click all the traffic lights” puzzles.
async function verifyTurnstile(
token: string,
secretKey: string
): Promise<boolean> {
const response = await fetch(
'https://challenges.cloudflare.com/turnstile/v0/siteverify',
{
method: 'POST',
headers: { 'Content-Type': 'application/x-www-form-urlencoded' },
body: `secret=${secretKey}&response=${token}`,
}
);
const result = await response.json();
return result.success;
}
Why this matters: Without protection, your AI endpoint becomes a target for prompt injection attacks, cost-based denial of service (running up your API bill), or scraping. Turnstile is free and adds maybe 100ms of latency. Worth it.
Hop 2: The Worker
Cloudflare Workers are serverless functions that run at the edge—in data centers worldwide, close to your users. If you’ve deployed applications on Kubernetes, think of Workers as pods that auto-scale globally without you managing the infrastructure.
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
if (url.pathname === '/ask' && request.method === 'POST') {
const body = await request.json();
// Verify the human
const isHuman = await verifyTurnstile(
body.turnstileToken,
env.TURNSTILE_SECRET_KEY
);
if (!isHuman) {
return new Response('Verification failed', { status: 403 });
}
// Forward to AI Search
return handleAskEndpoint(body.q, env);
}
// Serve the UI
if (url.pathname === '/') {
return new Response(generateHTML(env), {
headers: { 'Content-Type': 'text/html' },
});
}
return new Response('Not found', { status: 404 });
},
};
The pattern here is familiar: route requests to the right handler based on path and method. It’s not that different from configuring Ingress rules in Kubernetes. The difference is you’re writing TypeScript instead of YAML, and deployment is wrangler deploy instead of kubectl apply.
Hop 3: AI Search — The Managed RAG Pipeline
Here’s where things get interesting. Cloudflare AI Search is a fully managed RAG service. When you send a query, it:
- Embeds your query using Workers AI
- Searches the Vectorize index for semantically similar content
- Retrieves the relevant chunks from your indexed documents
- Generates a response using a Workers AI LLM, grounded in the retrieved context
async function queryAISearch(
question: string,
env: Env
): Promise<AISearchResponse> {
const response = await fetch(env.KB_SEARCH_URL, {
method: 'POST',
headers: {
'Authorization': `Bearer ${env.AUTORAG_API_TOKEN}`,
'Content-Type': 'application/json',
},
body: JSON.stringify({
query: question,
max_num_results: 5,
}),
});
return response.json();
}
What’s in my knowledge base? I uploaded these to an R2 bucket, and AI Search automatically indexes them:
- My resume (PDF)
- Professional certifications
- Transcripts of past interviews
- Blog posts from cloudnativenotes.com
The indexing pipeline runs every 6 hours, converting documents to markdown, chunking them, creating embeddings, and storing the resulting vectors. If I update my resume, the index updates automatically.
Hop 4: AI Gateway — Observability and Guardrails
This is the layer that makes production AI applications viable. AI Gateway sits in front of your AI traffic and provides:
- Logging and analytics — every request, response, latency metric, token count
- Rate limiting — protect against runaway costs
- Caching — serve identical responses from cache
- Guardrails — content moderation for prompts and responses
The concept of a gateway isn’t new and Cloudflare’s AI Gateway serves a similar purpose: it’s a proxy for AI traffic that provides observability without changing your application code.
 )
)
Guardrails: Content Safety at the Edge
Guardrails uses Workers AI models to evaluate content against safety categories. You can configure each category to flag (log for review) or block (reject the request).
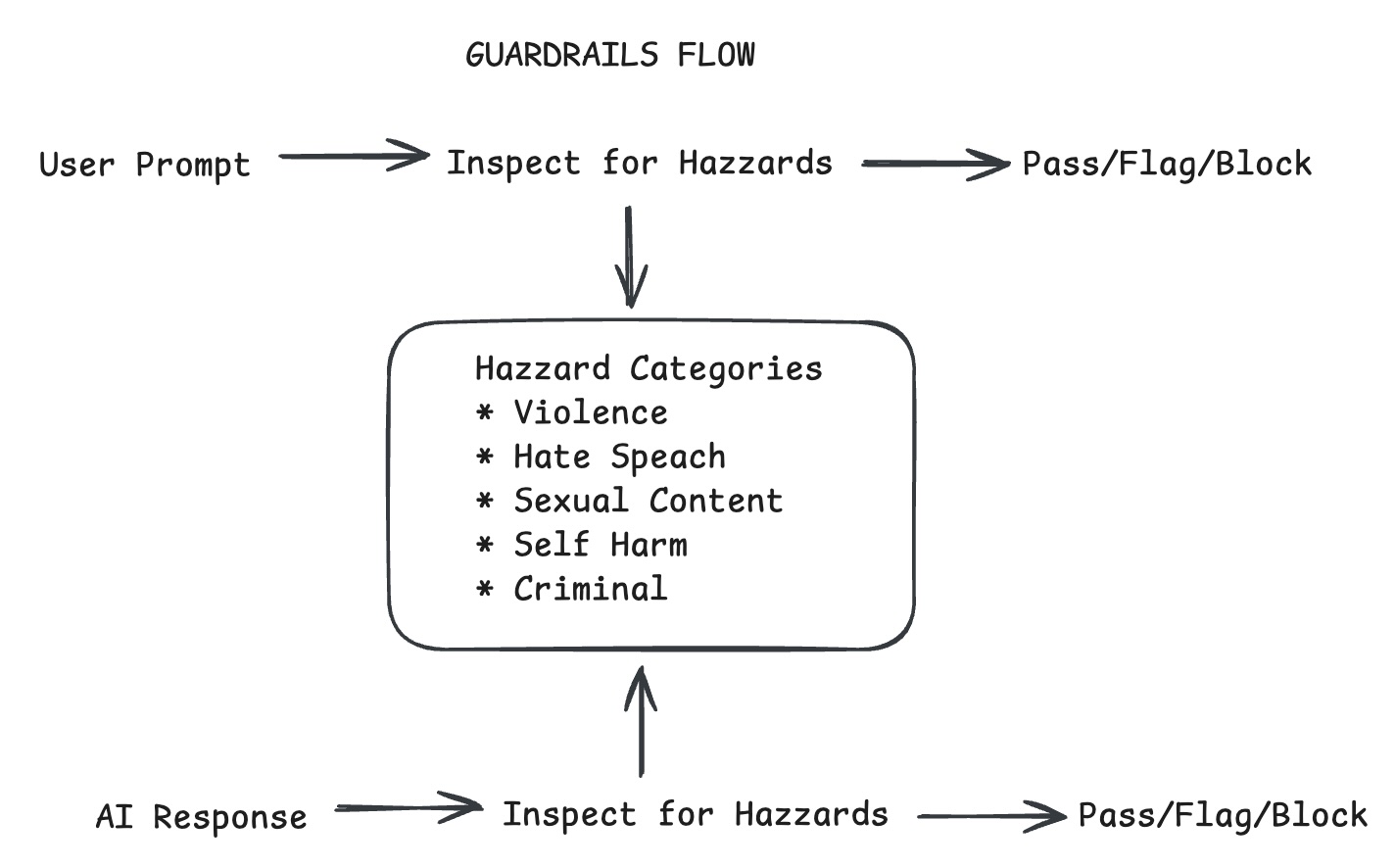
To enable Guardrails:
- Navigate to AI Gateway in the Cloudflare dashboard
- Select your gateway → Guardrails tab
- Toggle On
- Configure hazard categories for prompts and responses
- Choose Flag or Block for each category
One tradeoff to know: Guardrails buffers the complete response for analysis, which prevents true token-by-token streaming. I handle this with client-side streaming animation. The response arrives complete, then renders character-by-character for a smooth UX:
async function animateResponse(text: string, element: HTMLElement) {
for (let i = 0; i < text.length; i++) {
element.textContent += text[i];
await sleep(15);
}
}
Configuration: wrangler.toml
For those who want to deploy their own version, here’s what your wrangler.toml structure looks like. If you’re familiar with Terraform, think of this as your configuration file:
name = "careerstack-agent"
main = "src/worker.ts"
compatibility_date = "2024-01-01"
[vars]
AI_GATEWAY_BASE_URL = "https://gateway.ai.cloudflare.com/v1/<account_id>/<gateway_name>"
KB_SEARCH_URL = "https://api.cloudflare.com/client/v4/accounts/<account_id>/ai-search/<bucket>/ai-search"
TURNSTILE_SITE_KEY = "<your_turnstile_site_key>"
# Secrets are set via: wrangler secret put <SECRET_NAME>
# AUTORAG_API_TOKEN
# TURNSTILE_SECRET_KEY
Why Cloudflare?
I’ve deployed infrastructure on AWS, GCP, Azure, and now Oracle Cloud. I’ve seen what it takes to build production systems at scale. Here’s why I chose Cloudflare for this project:
The integrated platform is remarkable. Workers + R2 + AI Search + AI Gateway + a Vector store all work together seamlessly. No need to deploy separate services, configure networking between them, manage secrets, set up monitoring dashboards. Here, it’s all integrated.
The pricing is almost unbelievable. Most of what I’m using is free tier or pennies per request. For a personal project, this matters. For startups, this is transformative.
The developer experience is excellent. wrangler dev gives you local development. wrangler deploy pushes to production globally in seconds. No Dockerfiles, no CI/CD pipelines to configure, no Kubernetes manifests. Just code and deploy.
They’re innovating fast. AI Search went to open beta in April 2025. Guardrails launched in February 2025. They’re shipping meaningful features monthly. The ecosystem is evolving rapidly.
Try It Yourself
The code is open source: github.com/mattkferguson/careerstack-agent
The agent is live: mattv2.careerstack.app
Ask it about my experience with Kubernetes, Terraform, cloud architecture, or anything else in my background. It’ll answer based only on what I’ve told it with no hallucinations.
If you build something similar, I’d love to hear about it. Find me on LinkedIn or drop a comment on cloudnativenotes.com.